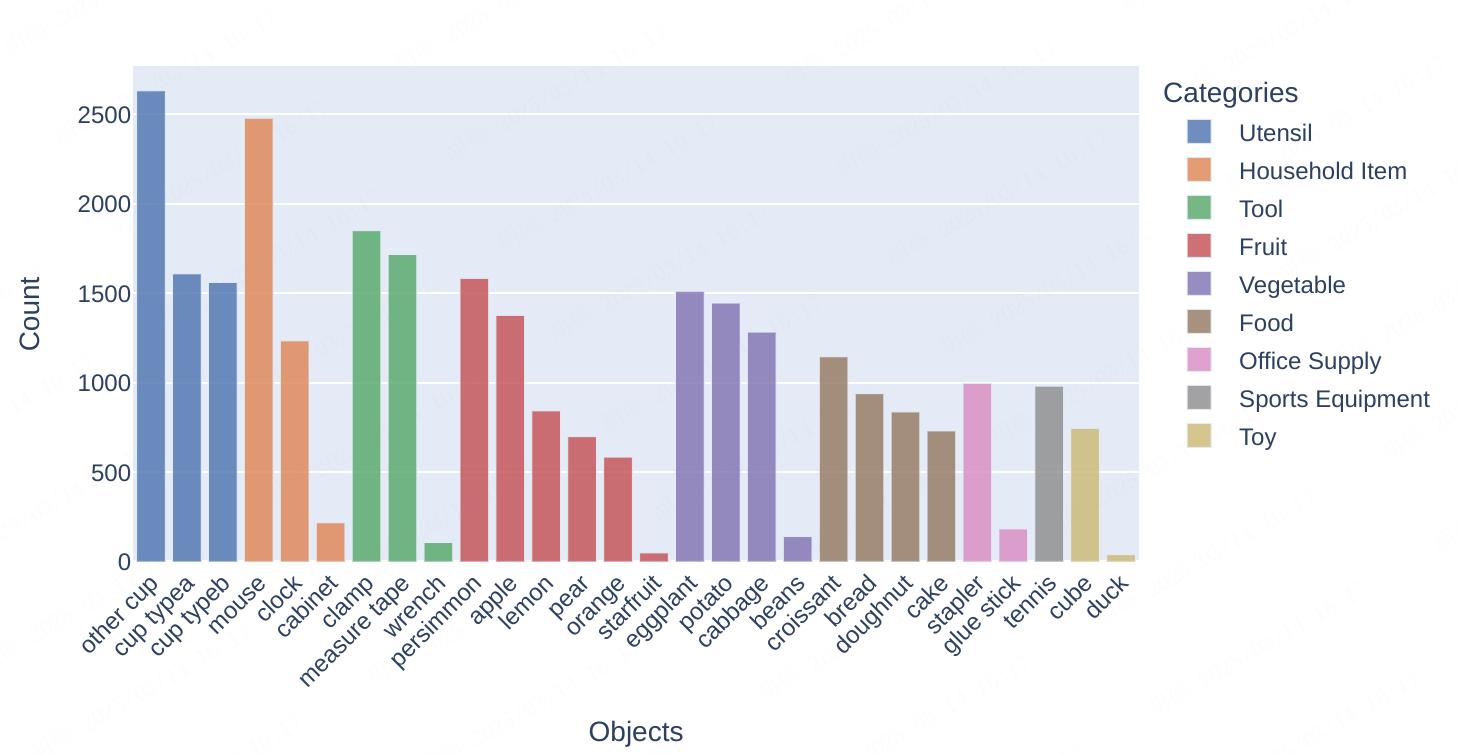

This dataset captures humanoid performance in tabletop tasks such as pick-and-place, pouring, and insertion across diverse environments with varying conditions, objects, and scene layouts. It incorporates multiple humanoid robots and dexterous hands to enhance variability and adaptability. Vision data is collected using the OAK-D W 97 camera, providing a wide field of view to align with the humanoid's perspective. The dataset includes recordings from Fourier GR1-T1, GR1-T2, and GR2 humanoids, along with two types of Fourier Dexterous hands featuring six and twelve degrees of freedom. By integrating diverse hardware configurations, this dataset supports robust learning and adaptability in real-world scenarios.
